






进行了大样本量实验(如微生物多样性测序)后,如何对样本进行有效且准确的分类,并且获得特征的重要性结果?
一、概念
01 简答题·随机森林可以解决什么问题?
随机森林是一种常用的机器学习算法,可以用于解决分类问题和回归问题。
02 名词解释题·何谓决策树?何谓随机森林?
决策树可以简单地理解为达到某一特定结果的一系列决策。
预测贷款用户是否具有还款能力?首先判断用户是否拥有房产,如果是,则可以偿还,否则继续判断。然后判断用户是否结婚,如果是,则可以偿还,否则继续判断。接着判断月收入指标,如果大于4k,则可以偿还,否则不能偿还。决策便是采用这样的树形结构,由包含样本的全集,对不同属性节点层层推导,直到无对应属性测试,最终获得分类。
随机森林是由很多随机创造的决策树构成的森林,每棵树之间沒有关联,随机森林将单颗树的输出结果整合起来生成最终的输出。
二、延伸
03 论述题·构造随机森林的步骤?
Step1. 随机抽样,训练决策树;
Step2. 随机选取属性作为节点分裂属性;
Step3. 重复步骤2直到不能分裂为止;
Step4. 建立大量决策树形成森林。
04 开放题·随机森林的优点有哪些?
1. 可以判断特征的重要程度;
2. 可以判断出不同特征之间的相互影响性;
3. 容易实现;
4. 若有大部分的特征缺失,仍能保持准确度;
5. 不容易过拟合;
6. 训练时可以并行操作,速度快。
三、研究
05 实践题·随机森林的云上分析工具在哪找?
当然是欧易云平台!本次介绍的这款小工具,只需两个输入文件,即可获得建立随机森林分类模型特征集的重要性信息。特征的选择是决定使用哪些特征来做决策判断的关键,其中样本集越大机器学习算法越准确,因此建议进行分析的数据组内有生物学重复且单组样本大于50。
【输入数据矩阵】
【输入分组文件】
在一个训练数据集中,每个样本的属性可能存在多个,不同属性的作用大小不一哦。
【输出MeanDecreaseGini 系数图】
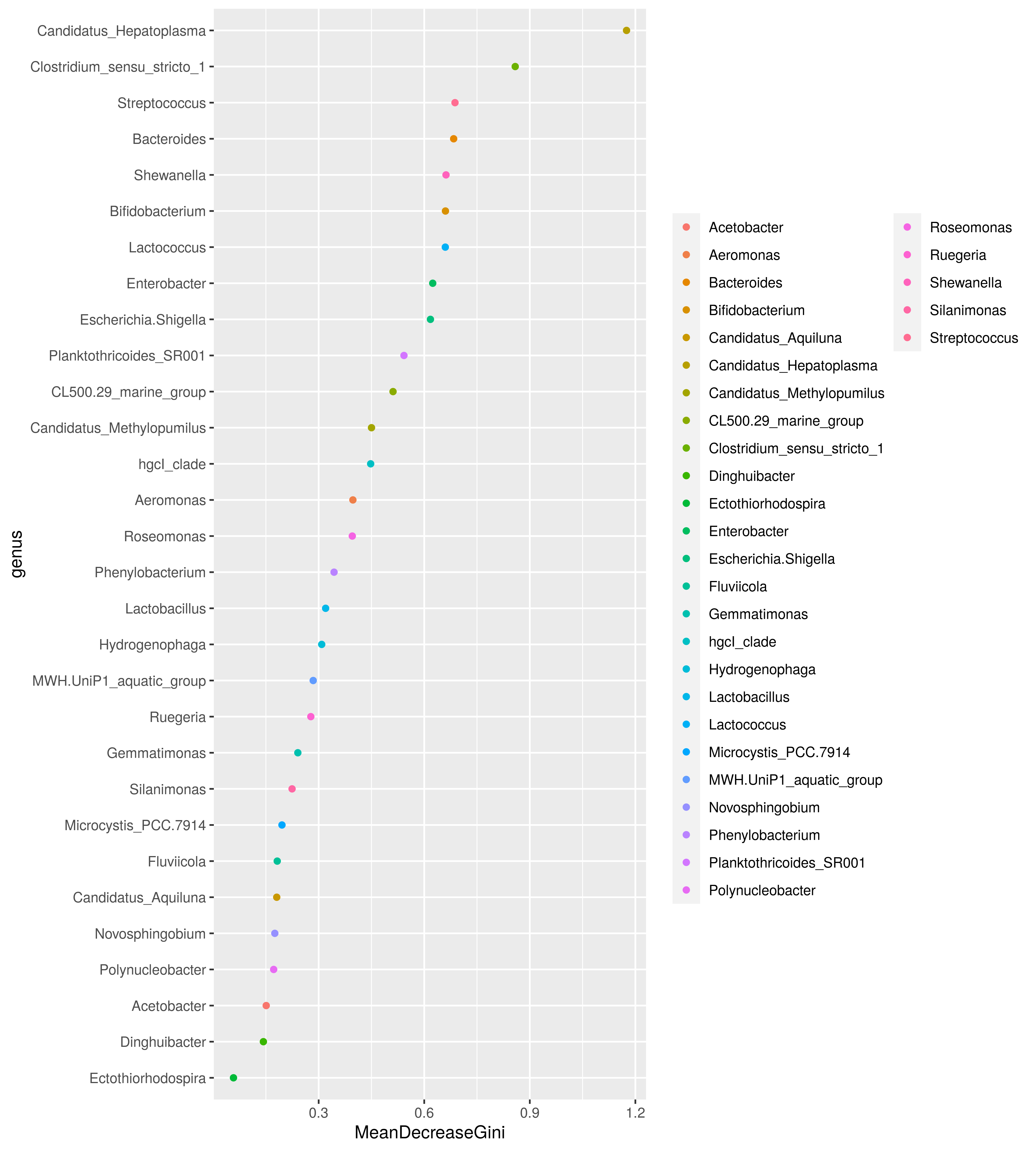
(横坐标为MeanDecreaseGini值,用来评判物种对模型分类的情况。MeanDecreaseGini 值越大,说明类别分类情况越好。纵坐标为 biomarker,按照 MeanDecreaseGini 系数的大小降序排列。注意:该图是根据输入文件的特征数目绘制。)
06 想象题·获得了特征后还能做些什么?
构建模型、绘制ROC曲线、混淆矩阵等等,下回小编便带大家熟悉ROC曲线的绘制,敬请期待~
文末彩蛋
看到这里的老师有福了~诚意满满的小编其实这次有给大家准备礼物哦~ 随着高通量测序的不断发展,单组学研究日趋成熟,多个组学整合越来越为研究的热点。其中,相关性分析是多组学分析中常见的分析方法之一,在此各大高校开学之际,欧易生物转录业务线推出免费R语言培训课程之相关性分析在多组学中的应用、原理及实战,助力广大老师科研工作。
本次培训主要内容:
1. 相关性分析在多组学中的应用
2. 常用相关性分析方法以及原理
3. 组学数据前期处理和分析实战
课程对象:
从事生命科学、医学领域研究对R语言感兴趣的科研工作者
培训时间:
2021年3月24日(周三) 19:30-20:30
报名方式和培训地点:
1. 添加下方欧易生物转录调控交流qq群(746716637)即可报名
2. 建议R语言零基础的老师可以先看一下 B站上欧易生物R语言视频的基础课程(https://search.bilibili.com/all?keyword=欧易生物 R语言)进行预习,听课效果更佳哦~